我国居民保险购买行为的决策树模型分析
 作者
作者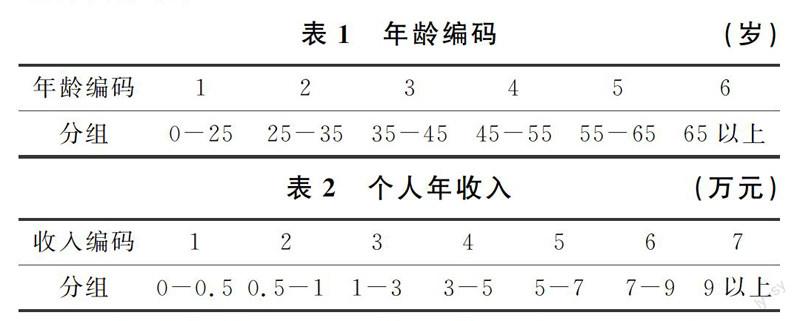


摘 要:近几年许多行业都步入大数据时代,但数据挖掘技术在我国保险领域的应用相对不多,并且我国保险公司也要考虑通过改变传统的经营方法来提升业绩,因此加大对数据的利用力度,过渡到数字化营销模式对保险公司来说十分关键。主要研究决策树算法在保险公司客户识别方面的应用,根据加入误分代价的决策树模型建立的分类规则,找出了影响我国居民是否购买保险产品的主要因素。
关键词:决策树;误分代价;基尼指数
中图分类号:F23 文献标识码:A doi:10.19311/j.cnki.1672-3198.2019.35.059
1 数据处理
选取 2015 年中国综合社会调查数据,根据相关研究选取其中的性别、年龄、个人年收入、是否拥有城市/农村基本医疗保险情况这四个影响因素。性别是名义变量,给男性赋值 1,女性赋值 2。将年龄以及个人年收入进行分段划分,并且对这两个影响因素数据进行离散化处理。
初始数据共有 10968 条,对其进行精简,只保留明确回答是否购买了商业医疗保险的数据,即购买了或是未购买的,凡是回答「无法回答、拒绝回答、不知道、不适用」的都不适用于本文的研究,故直接将其舍去,处理后的数据为 10747 条。对于其中个人年收入的缺失值对其进行同类插补将其补齐。最后得到的数据中购买商业医疗保险的居民有 950 个,未购买商业医疗保险的居民有 9797 个。
2 决策树分析
2.1 样本不平衡处理
由于本文中购买商业医疗保险的居民有 950 个,未购买商业医疗保险的居民有 9797 个,样本存在严重的不平衡性,因此我们在建模时要对购买了商业医疗保险的样本增加误分代价。
2.2 模型建立
决策树是使用类似于一棵树的结构来表示类的划分,树的构建可以看成是变量(属性)选择的过程,内部节点表示树选择哪几个变量(属性)作为划分,每棵树的叶节点表示为一个类的标号,树的最顶层为根节点。本文用 CART 决策树(回归树)对居民是否购买医疗保险进行分类,该算法是一个二叉树,即每一个非叶节点只能引申出两个分支,因此十分适合用于本文的研究。将处理过后的 10747 条样本划分为训练集和验证集,随机抽取 80% 为训练集,剩下的 20% 为验证集。
决策树算法中包含最核心的两个问题,即特征选择和剪枝,关于特征选择目前比较流行的方法是信息增益、增益率、基尼系数和卡方检验。CART 算法的特征选择就是基于基尼系数得以实现的,其选择的标准就是每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类。
依次计算出各个属性的基尼指数,并比较各属性基尼指数的大小得到个人年收入的基尼指数最大,从而确定个人年收入为第一个划分属性。个人年收入基尼指数计算步骤如下:
首先在对样本划分前,总的训练数据共有 2 类,即 N=2,其中参与商业保险的居民共有 760,未参与商业保险的居民共 7878,D=7118。
首先利用个人年收入进行划分,此属性共有 7 个值,K=7,即 a1=1,a2=2,a3=3, a4P=4,a5=5,a6=6,a7=7,数据集划分成 1 个集合,即 D1,D2,D3,D4,D5,D6,D7。
其中 Dk 表示包含个人年收入为编码取 k 的样本,Dk 表示总共有多少个样本位于此区间,其中购买了医疗保险的有 X 人,Py=1=P1=XDk 表示 a=k 时购买了商业医疗保险的人数占样本总体的比例,Py=-1=P2=Dk-XDk 表示未购买医疗保险的比例。
购买商业医疗保险的样本量比未购买商业保险的样本量少很多,因此使用加入误分代价的 CART 决策树模型,根据样本中购买了医疗保险和未购买医疗保险的人数比例进行设置误分代价如表 5。
进行建模得到的决策树风险如表 6。
从上表可以看出分类的标准误差很低,说明分类的效果比较理想,得到简单树形图为图 1。
2.3 模型结果解释
建模得到的特征重要性如表 7 所示。
可以看到影响到我国居民是否购买商业医疗保险的因素由重要性的从高到低依次为您个人去年全年的总收入、是否参加基本医疗保险、年龄、性别。从这点我们可以看出,收入是一个人是否会购买商业医疗保险的首要决定因素,当收入达到一个较高水平时居民会选择购买商业医疗保险,例如在本文的模型中可以看到收入高于 9 万元时居民会购买商业医疗保险,这说明我国居民在家庭较为富裕的情况下才会考虑为自己购买医疗保险增加保障。
对于保险公司来说,需要在营销时着重了解潜在客户的收入情况,将收入较高的潜在客户作为首要推销目标,降低营销成本。
参考文献
[1]王星,谢邦昌,戴稳胜.数据挖掘在保险业中的应用[J].数据,2004,24(4):50-51.
[2]王书爽.基于后修正贝叶斯决策树模型的保险企业营销决策[J].统计与决策,2013,14(3):180-182.
[3]Zhang Y,Chi 在 X,Xie F D,Li N.A weights-based accuracy evaluation method for multi class multipliable classifier [J].Journal of Computational Information Systems,2008,4(2):589-594.
[4]Bolton R N,Kennan P K,Bramlett M D.Implications of loyalty program membership and service experiences for customer relation and value [J].Journal of the Academy of Marketing Svience,2000,20(1):95-108.
作者 王姗姗