经济普查数据的分析与挖掘
 作者
作者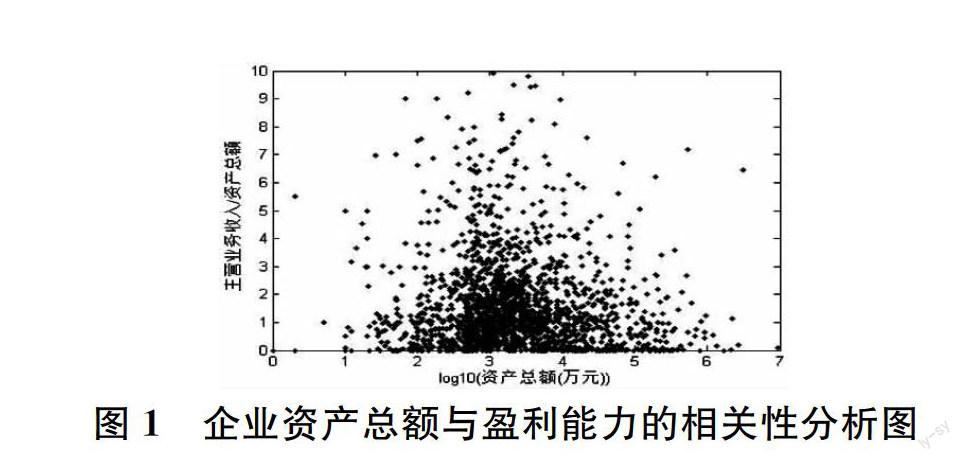
摘 要:通过相关性分析(Correlation)与支持向量机(Support Vector Machine)对经济普查系统中的部分典型数据进行具体的试验与分析:研究了企业的资产总额、高学历员工比例、女性员工比例与企业盈利能力的相关性,也研究了企业机构类型与其高学历员工比例的关系;并利用数据分析与挖掘技术对经济普查数据进行分析,从海量数据中发现知识,验证了该系统的可操作性和先进性,以期利用这些统计数据为我国的社会与经济发展服务。
关键词:经济普查系统;数据挖掘;支持向量机
中图分类号:D9
文献标识码:A
文章编号:1672-3198(2015)25-0229-03
0 引言
为了全面掌握国民经济的发展规模、结构和效益等情况,我国于 2008 年进行了第二次全国经济普查。这次普查的标准时间点为 2008 年 12 月 31 日,时期资料为 2008 年度,普查对象是在我国境内从事第二产业、第三产业的全部法人单位、产业活动单位和个体经营户。普查内容主要包括单位基本属性、就业人员、财务状况、生产经营情况、生产能力、原材料和能源消耗、科技活动情况等。
针对经济普查中收集的大量数据,有必要利用数据分析与挖掘方法对其分析,并通过相关性分析(Correlation)与 SVM(Support Vector Machine,支持向量机)进行具体试验,充分利用这些统计数据为我国的社会与经济发展服务,使我国在统计机构信息系统的研究水平达到或超过国外的水平。
1 经济普查统计指标解释
开展经济普查,不仅是为了掌握重要的国情国力,而且还要通过普查在人力、物力上的特殊优势,使普查制度设计成为推动经常性统计制度科学性的极好机会,发挥普查工作在整个统计工作中的基础地位。
本次经济普查收集了 23,028 家各类型企业的各 66 项数据,总计 1,522,488 条。为了方便对如此繁多的数据进行解读,发现知识,拟按下列经济普查统计指标进行分类、统计。
(1)登记注册类型。主要分为三类:内资;港澳台资;外资。
(2)执行的会计制度。主要包括企业、事业、行政三种。
(3)机构类型。主要分为企业、事业、机关三种。
(4)控股情况。主要分为国有、集体、私人、港澳台、外商五种。
(5)隶属关系。主要分为中央、省、地、县四级。
(6)经济指标。主要包括主营业务收入与资产总计两项。
(7)人力资源。人力资源的调查较为细致,对同一人群,采用了性别、学历、技术职称、技术等级四种不同的分类方法。(注:多样的分类方法使调查结果数据内容更加丰富,更有价值,但细致的分类似乎对参与调查的企业造成一些困扰,导致很多数据是空的。在数据挖掘的过程中,相关数据为空的条目将被移除。)
2 基于数据分析与挖掘的普查数据分析
在前期分类、统计数据的基础上,针对一些特征数据,如不同类型企业、企业员工组成、经营状况等数据,进行数据分析与挖掘,并进行相关性分析与 SVM 试验,所得的研究结论可供相关部门参考。
2.1 数据分析与挖掘算法选择
数据挖掘分类技术,主要有决策树法、贝叶斯法、神经网络法和粗糙集等方法。而近几年来,作为新兴智能数据挖掘技术,SVM 主要用于非线性回归领域,能更好地解决小样本、非线性及高维模式识别问题、网络结构的确定问题、过学习与欠学习问题、局部极小点问题等。SVM 起源于二类分类问题,也可以用作多类分类,并基于结构风险最小化原则,直接进行样本集自组织学习训练来逼近系统非线性规律,容错和泛化性能优良。
针对特征数据的特点,选择 SVM 训练超平面,用超平面把不同类的企业分开,从而获得不同类别企业间差异的信息。使用 SVM 划分不同类别企业更大限度利用了所有的信息,训练所得的超平面可以明确显示两类企业各有多少家在超平面的这一边,又各有多少家在超平面的另一边。根据 SVM 的原理,训练得到的超平面是把不同类分开的最优超平面,因此由该超平面得到的分类结果,其实就是各类不同企业的最大差异。用 SVM 对两类企业分类等价于将两类企业的差异最大化。
2.2 企业资产总额与盈利能力的相关性
研究企业的资产总额与盈利能力(主营业务收入/资产总额)的相关性,有助于发现企业规模与盈利能力的关系。
首先是数据的前处理。部分企业资产总额一栏填写值为 0,部分企业资产总额或主营业务收入一栏填写值为空,这些企业均被剔除,最终剩余 13,872 家企业。初步的相关性分析发现企业的资产总额与盈利能力的相关性并不直接,因此对资产总额取以十为底的对数。图 1 是 log10(资产总额)与企业盈利能力的相关性分析图。为了方便观察点的密度,仅显示了两千个点。
图 1 企业资产总额与盈利能力的相关性分析图
由图 1 可见,对于资产总额较小的、在一百万以下的企业,其盈利能力跳跃较大;对资产总额在四百万以上的企业,其盈利能力与 log10(资产总额)表现出较为明显的负相关。相关性分析表明,盈利能力与 log10(资产总额)的相关系数为-0.2981,其 95% 置信区间为[-0.3307,-0.2656]。
结果表明,对资产总额四百万以上的企业,其盈利能力与资产总额存在负相关性。造成这一现象的原因,可能是小企业更易管理,更容易从竞争较少的行业获益,而大企业往往管理不易,涉及的利益过于庞大,同行竞争也较为残酷,压低了平均利润水平。另一方面,也可能是小企业采取的会计制度不如大企业严格,夸大了收益。这一结果在一定程度上支持了股市投资的一个观点,就是小公司的股票上涨更快,这个结论也与美股市场过去百年间的统计结果相吻合。
2.3 企业高学历员工比例与盈利能力的相关性
研究高学历员工比例(研究生及其以上员工人数/员工总数)与盈利能力(主营业务收入/资产总额)的相关性,有助于考察高层次人才对企业盈利能力的影响。
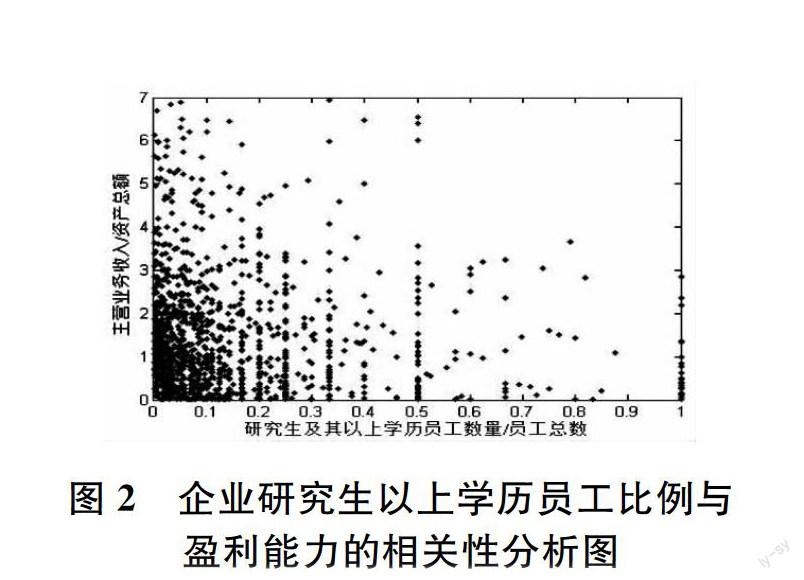
首先是数据的前处理。部分企业资产总额或员工总数一栏填写值为 0,部分企业资产总额或主营业务收入或员工总数或研究生及其以上员工总数一栏填写值为空,这些企业均被剔除。研究生数量为 0 的企业过多,本文将其剔除。最终剩余 1,313 家企业。图 2 是企业研究生以上学历员工比例与盈利能力的相关性分析图。
图 2 企业研究生以上学历员工比例与
盈利能力的相关性分析图
实验采用 Matlab R2007a 编程,运行在奔腾双核 CPU E5200(2.50GHz、2.49GHz),内存 3GB 的个人计算机上,运行时间约 7s。
由图 2 可见,在研究生及其以上员工比例大于 0 的企业里(1,313 家,约占企业总数 5669 家的 2316%),绝大多数企业研究生及其以上员工比例在 10% 以下,研究生及其以上员工比例越高,企业数量越少,但在 100% 的位置有显着的峰值,即有不少企业所有员工都是研究生及其以上学历,这些企业或许是从事研究性工作的研究所或咨询机构。从图上看,企业盈利能力与研究生及其以上员工比例的相关性并不显然,这是由于绝大部分企业集中在坐标原点附近。相关性分析表明,企业盈利能力与研究生及其以上员工比例的相关系数为 0.0192,其 95% 置信区间为[00157,0.0227],可靠性较盈利能力与 log10(资产总额)稍差,但都为正值。即,企业盈利能力与研究生及其以上员工比例有极为轻微的正相关。
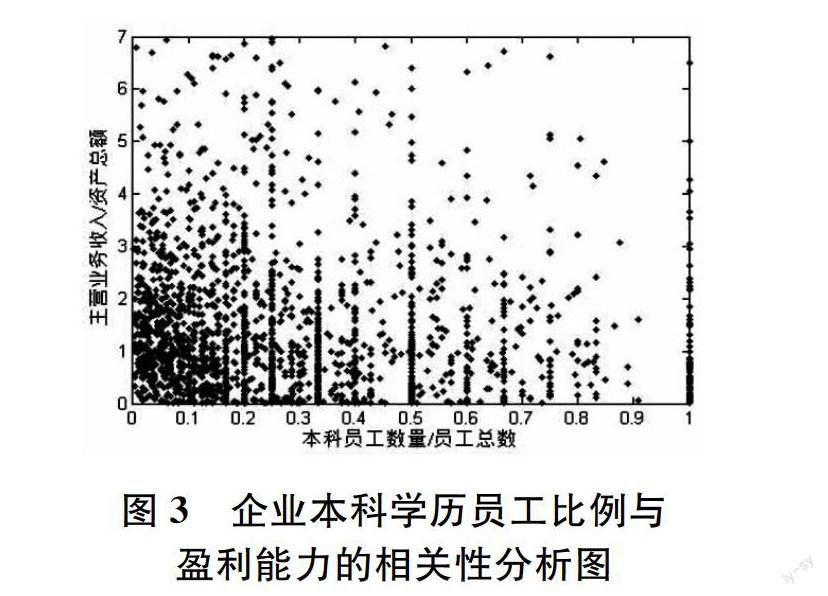
对本科员工比例与盈利能力的相关性分析,取得了类似的结果。图 3 为 2000 家企业的本科学历员工人数比例与盈利能力(图 3)。企业盈利能力与研究生及其以上员工比例的相关系数为 0.0183,其 95% 置信区间为[0.0154,0.0212],可靠性较研究生及其以上员工比例与盈利能力稍差,但都为正值。
图 3 企业本科学历员工比例与
盈利能力的相关性分析图
结果表明,高学历并非显着的导致高产出。尽管学历依然受到重视,高学历员工比例高一定程度上代表了高的科技含量,但这一特色并未明显的在市场上转化为直接的经济效益。这一结果有些耐人寻味,但的确与股市的一个选股原则缺失相对应,即上市公司的高学历员工比例并未被列为选股原则之一。由此推论,不仅在中国,在世界各国,都可能存在「高学历并非显着导致高产出」这一现象。导致这一现象的深层次原因可能是:(1)高学历学生进入公司无法应用所学;(2)企业招聘高学历学生,很大程度出于装点门面考虑;(3)高学历学生斗志减弱,倾向于进入稳定的、盈利少的事业单位而非竞争激烈的企业单位等因素;(4)亦或拥有较高比例高学历员工的企业往往较为正规,遵守的会计制度更为严格;等等。
2.4 企业女性员工比例与盈利能力的相关性
对于招收女性员工,企业往往徘徊不定,因为招收女性员工对企业效益同时具有正面与负面的影响。其正面影响,是企业需要一定比例的女性员工,来调节工作气氛,促进生产效率;其负面影响,是女性员工往往会因生子而耽误工作。通过数据挖掘的方法,分析企业女性员工比例与盈利能力的相关性,可以发现女性员工对企业盈利的影响。
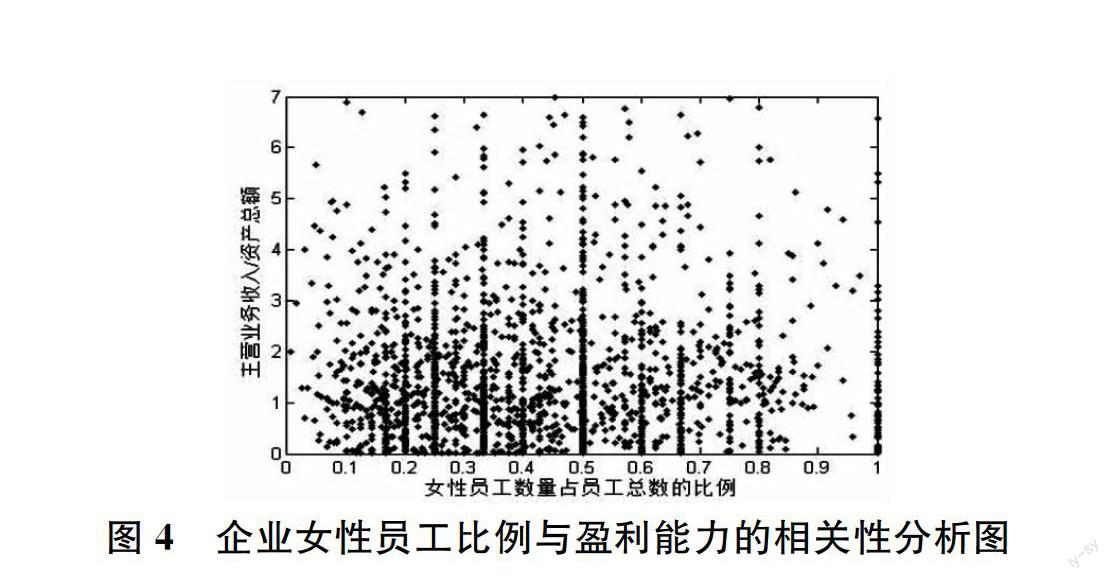
首先是数据的前处理。部分企业资产总额或员工总数一栏填写值为 0,部分企业资产总额或主营业务收入或女性员工数量或员工总数一栏填写值为空,这些企业均被剔除,最终剩余 14,789 家企业。图 4 是企业女性员工比例与盈利能力的相关性分析图。为了方便观察点的密度,仅显示了两千个点。
图 4 企业女性员工比例与盈利能力的相关性分析图
由图 4 可见,企业女性员工比例与盈利能力的关系具有分段性。对于女性比例在 30% 以下的企业,女性员工比例与盈利能力似乎存在一定的正相关,对于女性比例在 30% 以上的企业,女性员工比例与盈利能力似乎存在一定的负相关。因此本文将女性员工比例分为[0,0.3]与[0.3,1]两个区间。相关分析的结果表明,当女性员工比例小于 30% 时,女性员工比例与盈利能力的相关系数为 0.0129,其 95% 置信区间为[00114,0.0143];当女性员工比例大于 30% 时,女性员工比例与盈利能力的相关系数为-0.0235,其 95% 置信区间为[-0.0259,-0.0218]。
结果表明,当女性员工比例在 30% 以下时,女性员工比例与盈利能力存在轻微的正相关,当女性员工比例在 30% 以上时,女性员工比例与盈利能力存在稍明显的负相关。即,女性员工的比例不宜过低,也不宜过高,而是以维持一定的比例为佳。造成这一现象的原因,可能是一定比例的女性员工,可有效调节工作气氛,促进员工整体的生产效率;而当女性员工比例过半时,这一调节效果则容易失效,并且女性员工往往会因生孩子而耽误工作,造成企业营业收入的下滑。
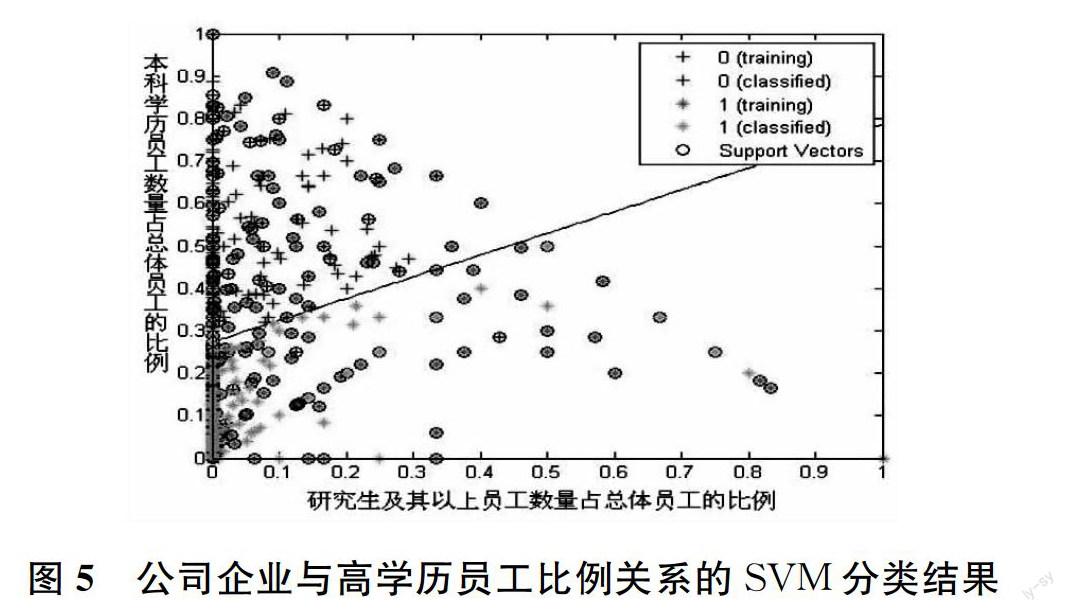
2.5 公司企业与高学历员工比例的关系
通过 SVM 方法对机构分类、试验,可以发现公司企事业与人力资源学历构成之间的关系。由于 SVM 本质上是对只有两类的问题进行分类,因此,需先把多类问题转化为两类问题,再用 SVM 分类。处理方法是,考虑某个机构类型时,把该类型标签设定为 1,其余类型标签设定为 0。
实验采用 Matlab R2007a 编程,运行在奔腾双核 CPU E5200(2.50GHz、2.49GHz),内存 3GB 的个人计算机上,运行时间约 8670s。
首先是数据的前处理。部分企业员工总数一栏填写值为 0,部分企业员工总数或本科学历员工总数或研究生及其以上员工总数一栏填写值为空,这些企业均被剔除。最终剩余 1,313 家企业。为了方便观察点的密度,图上只显示了 200 个点。
图 5 公司企业与高学历员工比例关系的 SVM 分类结果
如图 5,+ 号代表公司企业,*号代表其他类型的企业单位;深色的 + 号与*号代表被分为训练集的元素,浅色的 + 号与*号代表被分为测试集的元素;圆圈中的元素为支持向量。图中的直线是 SVM 判别直线。SVM 分类成功率为 81.20%,即约 80% 的企业单位集中在判别线之上的区域。
结果表明,公司企业与其他类型单位在员工学历构成的倾向上具有明显地差别,公司企业倾向于拥有更高比例的本科生,其研究生比例基本都在 30% 以下;其他类型单位则表现得较为零散。这可能是由于其他类型单位包含了事业单位、机关单位、社会团体、居委会、村委会等等,自身构成较为复杂。公司企业倾向于招收本科生的结果,与校园招聘会的现实接近,在各大公司企业的招聘章程里,本科生的需求量都是最大的。究其原因,首先是本科生基数远大于研究生及其以上学历学生,其次或许与公司企业注重企业文化的建设,本科毕业生单纯易于栽培有关;另外本科生薪资期待比研究生及其以上学历学生要低,精力却更年轻因而更充沛,更肯拼搏奋斗,性价比较高;最后,研究生或更高学历学生在校所学未必为公司企业所需;或许这些都是造成注重收益的公司企业更倾向于招收本科生的原因。
3 结语
通过相关分析与 SVM 方法,对系统的数据分析与挖掘功能进行了试验和分析,发现如下结论:
(1)企业资产总额与盈利能力存在一定的负相关,相关系数为-0.2981,其 95% 置信区间为[-0.3307,-0.2656]。
(2)企业高学历员工比例与盈利能力存在轻微的正相关,研究生及其以上员工比例与盈利能力的相关系数为 0.0192,其 95% 置信区间为[0.0157,0.0227],本科学历员工比例与盈利能力的相关系数为 0.0183,其 95% 置信区间为[0.0154,0.0212]。
(3)企业女性员工比例与盈利能力,当女性员工比例小于 30% 时,存在轻微的正相关,相关系数为 00129,其 95% 置信区间为[0.0114,0.0143];当女性员工比例大于 30% 时,存在稍大的负相关,相关系数为-0.0235,其 95% 置信区间为[-0.0259,-0.0218]。
(4)公司企业的员工学历构成与其他类型单位有显着地区别,用 SVM 分类可达到 81.20% 的分类正确率,其员工组成的特点是侧重本科生。
实验结果表明,用相关分析与 SVM 方法对机构分类,并通过数据分析与挖掘,可以从海量数据中发现大量知识,验证了该经济普查系统的可操作性和先进性。
参考文献
[1]四川省人民政府经济普查领导小组办公室.第二次全国经济普查概要[J].四川省情,2008,(8).
[2]全国经济普查条例[J].北京:北京统计,2004,(10).
[3]张敏敏.中国经济普查的数据挖掘方法研究[D].哈尔滨:东北林业大学,2005.
[4]对新一轮经济普查的几点思考[EB/OL].安徽统计信息网,2001-6-4.
[5]杨会志.数据挖掘技术的主要方法及其发展方向[J].河北科技大学学报,2000,(5):86-90.
[6]业宁,梁作鹏,董逸生,王厚立.一种 SVM 非线性回归算法[J].计算机工程,2005,(20).
[7]李望晨,张利平,王培承.基于 SVM 数据挖掘的国民经济序列补缺及预测—以青海省国民经济为例[J].工业技术经济,2010,(1).
[8]牟琦,毕孝儒,龚尚福,厍向阳.基于中间分类超平面的 SVM 入侵检测[J].上海:计算机工程,2011,(16).
作者 张丽虹